基本原理
利用数据表中主键不能重复的特点,通过构造重复的主键,使得数据库报错,并将报错结果返回到前端。
SQL说明函数
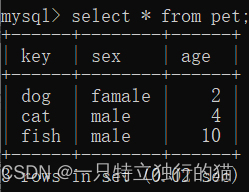
以pet数据表为例进行说明
rond():
返回[0,1)区间内的任意浮点数。
count():
返回每个组的列行数。
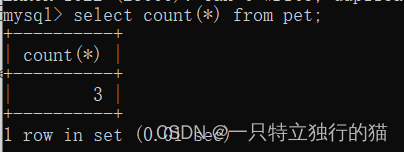
如,返回test表的行数。
select count(*) from pet;
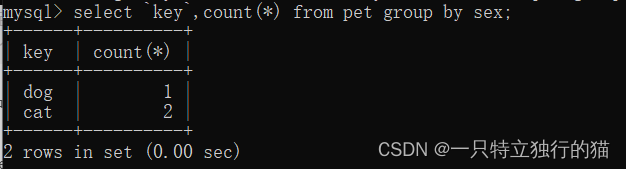
或者,返回pet表中性别分别为female和male的动物个数。
select count(*) from pet group by sex;
floor():
向下取整,得到整数。
floor(0.4)//结果为0
floor(0.99999)//结果为0
floor(1.0001)//结果为1
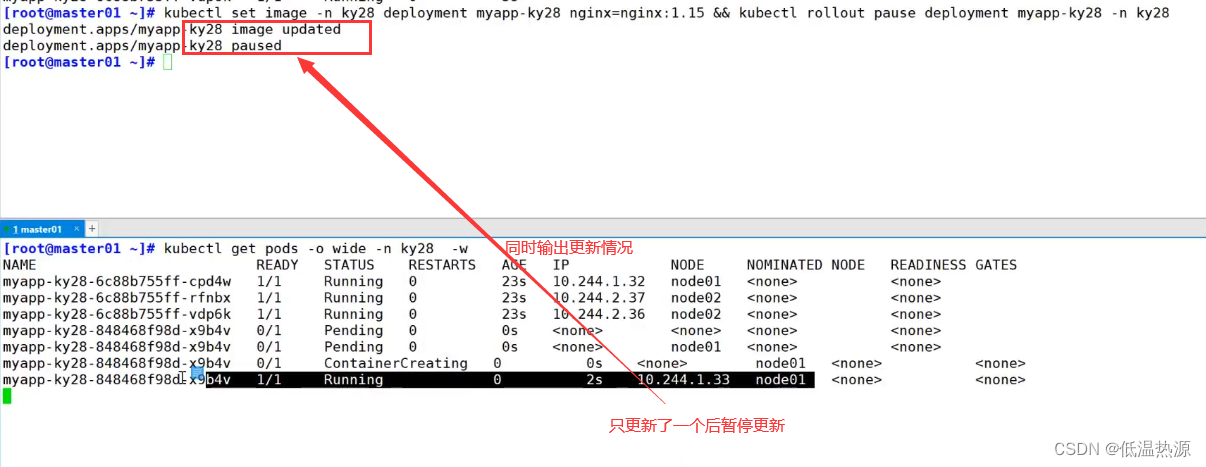
主键报错语句
通过构造下述语句,实现主键重复。
select count(*) from pet group by floor(rand(0)*2);
主键重复的原因:
1、首先,需要得知,floor(rand(0)*2)的计算结果。
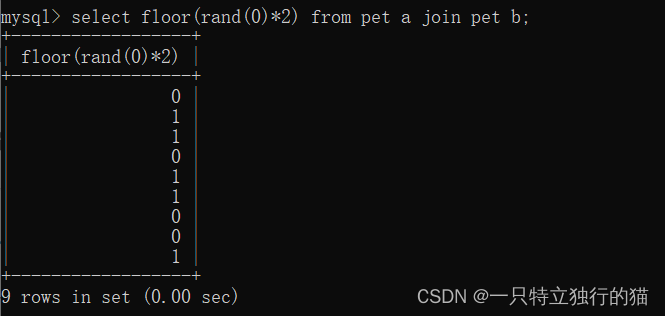
这里可以看出,floor(rand(0)*2)的计算结果前五位分别为,0、1、1、0、1。记住这5位结果,后面会用到。
2、其次,需要知道,group by语句的计算过程。
group by语句在执行时,首先会在内存中建立一个空白虚拟表,并将select后面的字段名称作为主键。这个虚拟表的结构和最终输出结果的结构一样。比如,查询select age,sex from pet group by key;。产生的虚拟表结构如下。(age,sex)为虚拟表的主键。
| age | sex |
|---|---|
在建立完成虚拟表后,根据SQL语句往虚拟表中填充数据。这里对于原pet表的每一行数据操作分为两步,第一步:依据group by语句后面的字段,获取这一行对应的字段值,并确认虚拟表中这个字段值是否发生重复。第二步:若发生重复,则将这一行与重复的行归为一组;若未发生重复,则再次获取group by后面的字段,将这一行对应的字段插入虚拟表。
3.最后,可以得到下述语句的执行过程。
这里,group by后面只是单纯的代表数字,不代表列。
select count(*) from pet group by floor(rand(0)*2);
①建立虚拟表pet_v
| floor(rand(0)*2)(主键,不显示) | count(*) |
|---|---|
②第一次执行floor(rand(0)*2),得到结果0。依据当前行的结果,去虚拟表pet_v中查询是否发生主键重复。发现未产生重复,于是第二次执行floor(rand(0)*2)得到1,将当前结果插入虚拟表。
| floor(rand(0)*2)(主键,不显示) | count(*) |
|---|---|
| 1 | 1 |
③第三次执行floor(rand(0)*2),得到结果1。去虚拟表pet_v中查询是否发生主键重复。发现产生重复,于是自增1。
| floor(rand(0)*2)(主键,不显示) | count(*) |
|---|---|
| 1 | 2 |
④第四次执行floor(rand(0)*2),得到结果0。去虚拟表pet_v中查询是否发生主键重复。发现未产生重复,于是第五次执行floor(rand(0)*2)得到1,将当前结果插入虚拟表。这时,发生了主键重复,系统报错。
| floor(rand(0)*2)(主键,不显示) | count(*) |
|---|---|
| 1 | 2 |
| 1 | 1 |
| 产生报错结果: | |
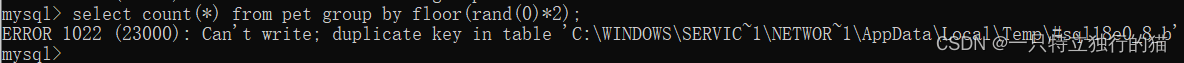 |